Inspired by an article in PNAS (https://www.pnas.org/content/117/22/11875) by some folks at NIH where they looked aerosols with a laser, I was interested in looking at the rate of aerosol spread from masks during talking and singing. This was in part because in the summer is was very difficult to acquire masks, quality was variable, and we were thinking about return to school in the fall.
I built a prototype from cardboard, but the system was super noisy. Enter the GF. I cut out and decorated a box (because the decoration is very important for the science part). The system looks like this:

Inside:

The basic premise is that the laser fluoresces the floating aerosol particles from that stuff coming out of your mouth and you can determine the size and frequency of the particles by imaging and analyzing the size. For a laser, I got the most powerful green laser pointer from amazon and grabbed my spouse’s mini IPad (in case I accidentally damaged the detector on the camera). Here is an example of droplets in front of the laser (a simulated cough):


So then I took Slo-Mo video (90ish frames a second) of myself speaking into the funnel on top, first counting to 15 in a normal voice and then shouting. I tried out various masks in one sitting including KN95s which are easily available now, a scarf mask my spouse ordered early on, N95 painter’s mask with outflow and and N95 from my friend Josh, a fabric mask with pleats I like to wear and a face shield. I kept myself hydrated. I analyzed the data by writing an OPENCV (computer vision library) program to identify the droplets and estimate size over the length of the movies. The program also deduplicates as good as I can for droplets which appear over multiple frames (floaters) and does some basic getting rid of super small stuff. It is not a perfect algorithm- but is pretty good for comparison purposes. Here is a sample of these droplets plotted the Y axis (down) is the frame number and the X axis (across) is the position on the portion of the laser that is detectible in the movies. Here is example unmasked:

A zoom in where you can my big slobber and lots of small bits coming out:
And the full pictures:


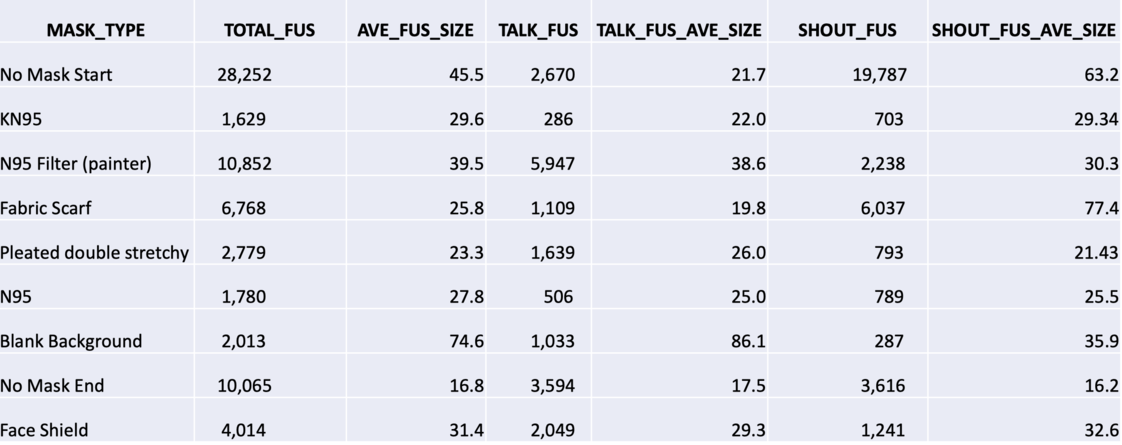
The results are here broken out into Talk period and shout period (without the overlap) and totals. These are all measured in Fluorescent Units (FUs):
And a graph minus the first No Mask attempt (which was for sure the most vigorous):
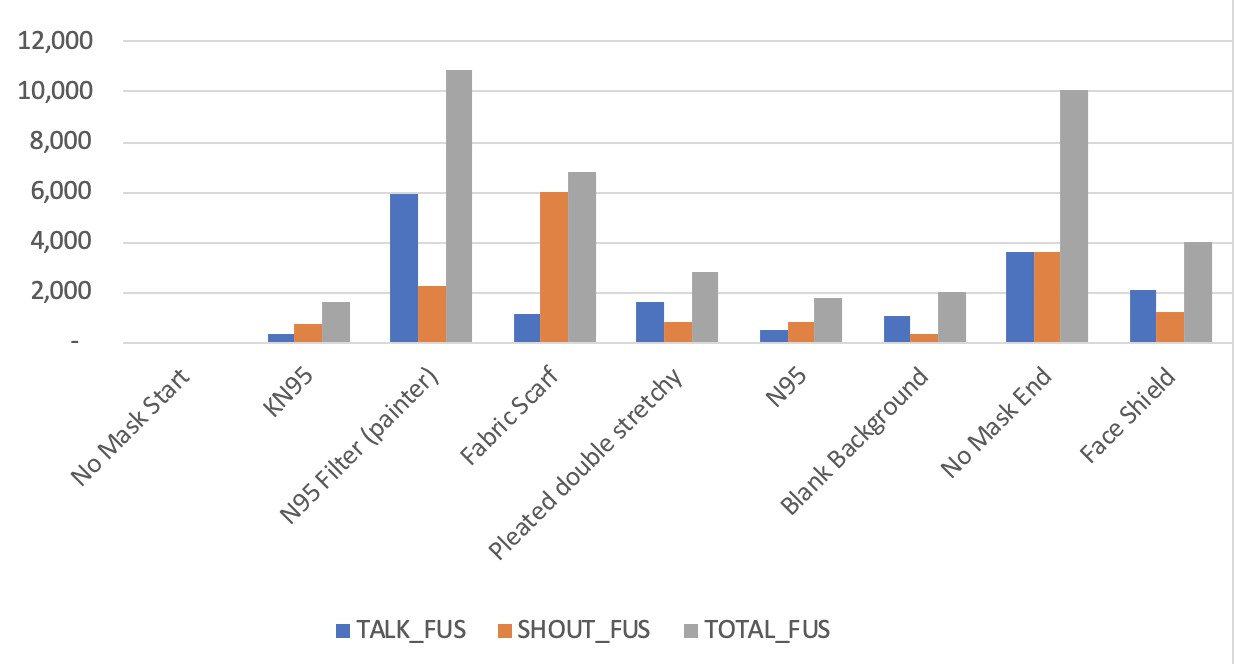
So a few take homes:
- Any “real mask” is better than none at preventing aerosols.
- Fabric scarfs are not “real” masks.
- N95 with outflow filters are the same for others as if you are wearing no mask. High FU units.
- N95s and K95s are just a bit above background.
- Shouting is worse in general than talking

In terms of total FUs: KN95 & N95, Pleat Fabric, Face Shield, Scarf, No Mask & Painters
For total particles detected over the sample period:
No Mask Start 621
KN95 55
Painters 275
Scarf 262
Pleat Fabric 119
N95 64
Background 27
No Mask End 598
Face Shield 128
So for number of particles: KN95, N95, Pleat Fabric, Face Shield, Painters N95
So nothing too surprising! If you can please, wear a mask in order to reduce transmission of COVID/flu and protect yourself and family. Stay Safe!
Just a note on sources of error here:
- I used a laser pointer here which isn’t a very clean laser source and it has the added problem of slowly fading over time until it is recharged. I didn’t want to shell out for a $500 laser to improve the source. This accounts for some of the background noise and means that I can’t really do multiple tests over the course of a day as the laser weakens.
- I only allowed 5 minutes between tests- this mostly is enough for the level of detection her to let the particles mostly pass out of the laser beam. However, this time could be extended.
- There is no real replication here- for sure doing this 5 times per mask in random order with measurements of background noise in the system would improve the accuracy (but probably require a better laser source for consistency (see #1) .
- I use pretty standard Canny edge detection in openCV tuned to avoid small repeated sources of error, but this could be much better implemented and tuned.
- Aerosol droplets are dependent on how much liquid you got to expel, here, I did rehydrate - but it is clear that for my first no mask attempt, which was also the first attempt for this data set, I had some “extra” spit to expel.
- These masks were all fresh and mostly unworn- for sure after you have been wearing a mask for 8 hours they likely perform differently. For example, I wear one of these doubled, pleated fabric masks as they are comfortable, but I find that they are pretty saturated with spit after a few hours when talking. This likely increases transfer both ways. I’ve taken to trying to wear disposable KN95s when I am going to speak with people or a group for any length of time.
So these results should only be viewed as a pilot where I tired to maintain a reasonable design.
Disclaimer: I am a scientist, but not an infectious disease expert. My reading from the current science is that aerosol droplets from superspreaders are bad and you shouldn’t inhale them.


 (I prefer them too!) The medical clinic we go to has just started not allowing gaiters and bandannas, I think because they’re basically just too thin. But I did read an article where researchers found the microfiber ones actually disperse MORE virus because they break up the breath droplets into smaller particles.
(I prefer them too!) The medical clinic we go to has just started not allowing gaiters and bandannas, I think because they’re basically just too thin. But I did read an article where researchers found the microfiber ones actually disperse MORE virus because they break up the breath droplets into smaller particles.